SDMX is a comprehensive, domain-neutral, ISO standard for Statistical Data and Metadata exchange, first released in 2004.
Let’s clear-up one misconception straight away – although SDMX stands for Statistical Data and Metadata eXchange – you should not let the “eXchange” part fool you into thinking that this is simply a file format – it is so much more!
The SDMX standard provides:
- Technical standards (including the Information Model)
- Statistical guidelines
- an IT architecture and tools
Taken together, the technical standards, the statistical guidelines and the IT architecture and tools can support improved business processes for any statistical organisation as well as the harmonisation and standardisation of statistical metadata.
sdmx.org
Domain neutral
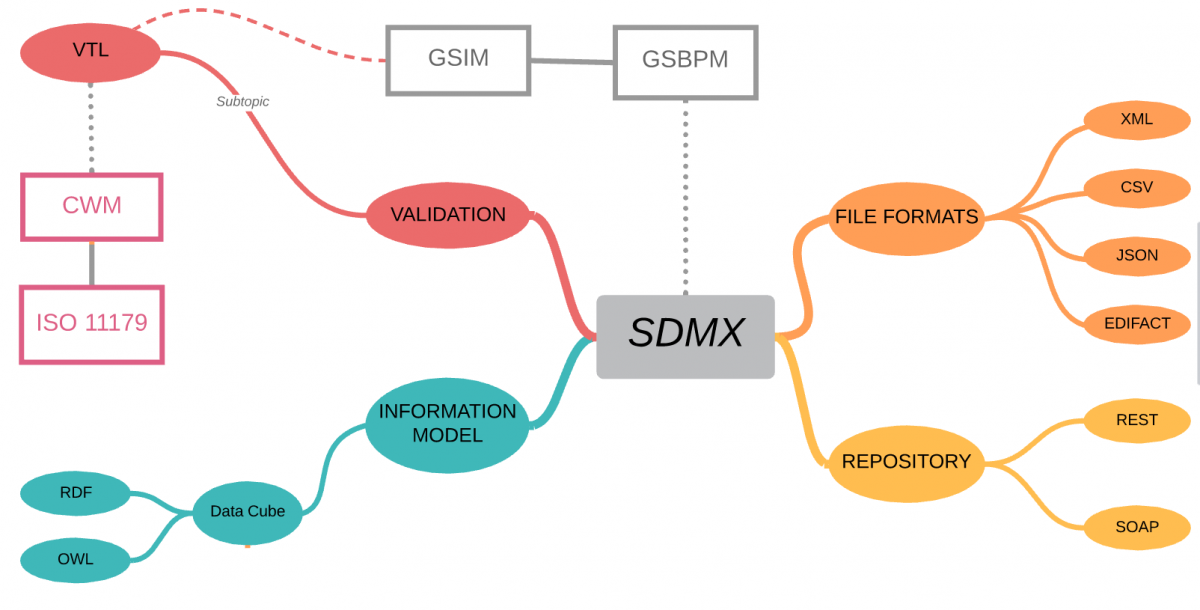
Although SDMX was established by international banking and government organisations, the information model is domain neutral, and because it is based on W3C Semantic Web standards, it aligns with the CDISC vision of linked data and biomedical concepts.
SDMX defines a vocabulary for describing Statistical data using W3C Data Cube which and so all domain-specific metadata is described using OWL ontologies – if this is new to you, then have a look at bioontology.org – The world’s most comprehensive repository of biomedical ontologies!
For this reason alone, SDMX provides a pathway to the CDISC vision of clinical trials analyses based on linked-data and biomedical concepts.
Comprehensive
In addition to the information model, SDMX contains statistical guidelines which cover the collection, processing, analysis and reporting of statistical data across organisations and are based on the Generic Statistical Business Process Model (GSPBM)
The statistical guidelines aim at providing general statistical governance as well as common (“cross-domain”) concepts and code lists, a common classification of statistical domains and a common terminology.
sdmx.org
Clinical trials typically involve data exchange across a network of Sponsors, Regulators, Vendors, Labs, CRO’s, etc. Each with different roles as data produces and consumers, different agreements on who can access what data when. These are all scenarios covered by the SDMX Statistical Guidelines and GSBPM.
Metadata repository
SDMX provides the specification for the logical registry interfaces, including subscription/notification, registration of data and metadata, submission of structural metadata, and querying, which are accessed using either REST or SOAP interfaces.
Metadata Repositories (MDR) are at early-stage adoption within Clinical Trials, so a key benefit of a standard interface is that it allows a period of experimentation/evolution on how the MDR is implemented with limited impact the rest of your analytics platform.
File interchange format
Well, yes! SDMX does also include file format standards for the exchange of data – XML, CSV, JSON are probably the key ones for use in clinical trials, allowing data transfer between languages and systems with minimal change.
Validation and Transformation Language
SDMX also includes a fully specified Validation and Transformation Language (VTL) which allows statisticians and data managers to express logical validation rules and transformations on data can be converted into specific programming languages for execution (SAS, R, Java, SQL, etc.)
Although the VTL language originated under the governance of SDMX, it was recognised that other communities could benefit and so VTL was designed to be usable in SDMX, DDI and GSIM
Summary
Why consider SDMX for use in clinical trials?
In short, because it’s a comprehensive, established standard which can be applied to any Statistical domain, and it ‘plays nicely’ with many other standards.
But what problem will it help solve? Typical use-cases might include:
- Creating vizualisations for Blind Review that take place before ADaM and TFL programming is completed,
- Implementation of CDISC standards using linked-data and biomedical concepts,
- Improved governance of data transfers between Sponsors, Regulators, Vendors and CRO’s
- Validation of open-source technologies and new languages such as R, Python or Julia,
- A standards standards-based Metadata Repository (MDR) interface that can remain constant from pilot through deployment regardless of implementation technology or vendor.
Even if you do not include SDMX, there are certainly parts that are worth consideration.